
13 통계 분석 기법을 이용한 가설 검정
13-1 통계적 가설 검정이란?
#기술 통계와 추론 통계
기술통계: 데이터를 요약해 설명하는 통계기법
ex) 사람들이 받는 월급을 집계해 전체 월급 평균을 구하는 것.
추론통계: 단순히 숫자를 요약하는 것을 넘어 어떤 값이 발생할 확률을 계산하는 통계 기법
ex) 수집된 데이터에서 성별에 따라 월급에 차이가 있는 것으로 나타났을 때, 이런차이가 우연히 발생할
확률을 계산. 이러한 차이가 우연히 나타날 확률이 적다면 성별에 따른 월급차이가 통계적으로 유의하다고 결론.
반대로 이러한 차이가 우연히 나타날 확률이 크다면 성별에 따른 월급차이가 통계적으로 유의하지 않다고 결론.
통계적 가설 검정
유의 확률을 이용해 가설을 검정하는 방법을 '통계적 가설 검정'이라고 한다.
'유의확률'은 실제로는 집단 간 차이가 없는데 우연히 차이가 있는 데이터가 추출될 확률을 의미한다.
13-2 t검정 - 두 집단의 평균 비교
*t 검정 : 두 집단의 평균에 통계적으로 유의한 차이가 있는지 알아볼 때 사용.
#compact 자동차와 suv 자동차의 도시연비 t 검정
1. mpg 데이터를 불러와 class, cty 변수만 남긴 뒤 class 변수가 "compact" 인 자동차와 "suv"인 자동차를 추출

2. t.test() 를 이용해 t 검정을 하자.
앞에서 추출한 mpg_diff 데이터를 지정하고, ~기호를 이용해 비교할 값인 cty변수와 비교할 집단인 class 변수를 지정.
t검정은 비교하는 집단의 분산이 같은지 여부에 따라 적용하는 공식이 다름.
여기서는 집단 간 분산이 같다고 가정하고 var.equal 에 T 를 지정하자.

1. 출력된 t검정 결과에서 'p-value'가 유의확률을 의미한다. 일반적으로 유의확률 5%를 기준으로 삼고,
p-value 가 0.05 미만이면 '집단 간 차이가 통계적으로 유의하다'고 해석한다.
실제로는 차이가 없는데 우연히 관찰된 확률이 5%보다 작다면 우연이라고 보기 어렵다는 것이다.
분석결과: compact 와 suv 간 평균 도시 연비 차이가 통계적으로 유의하다.
2. 'sample estimates' 부분을 보면 각 집단의 cty 평균이 나타나 있다. "compact"는 20 인 반면,
"suv"는 13이므로 "suv"가 "compact"보다 도시연비가 더 높다고 할 수 있다.
#일반 휘발유와 고급 휘발유의 도시 연비 t 검정
<분석결과>
p-value가 0.05 보다 큰 0.2875 이다.
실제로는 차이가 없는데 우연에 의해 이런 차이가 관찰될 확률이 28.75%라는 것이다.
13-3 상관분석- 두 변수의 관계성 분석
*상관분석: 두 연속 변수가 서로 관련이 있는지 검정하는 통계 분석기법
상관계수는 0~1사이의 값을 지니고 1에 가까울수록 관련성이 크다.
상관계수가 양수면 정비례, 음수면 반비례관계이다.
#실업자 수와 개인 소비 지출의 상관관계
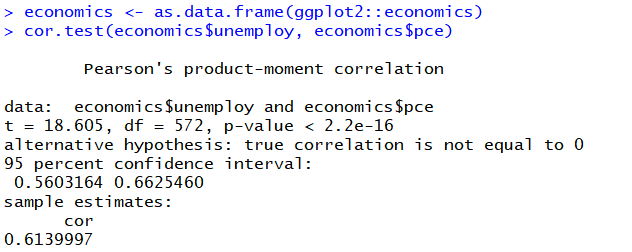
1. 출력결과를 보면 p-value 가 0.5 미만이므로, 실업자 수와 개인 소비 지출의 상관이 통계적으로 유의하다고 해석
2. 출력결과 맨 아래 'cor'이 상관계수를 의미한다. 상관계수가 양수 0.61 이므로, 실업자 수와 개인 소비 지출은 한 변수가 증가하면 다른 변수가 증가하는 정비례 관계임을 알 수 있다.
#상관행렬 히트맵 만들기
*여러 변수의 관련성을 한 번에 알아보고자 할 경우, 모든 변수의 상관관계를 나타낸 상관행렬을 만든다.
상관행렬을 보면 어떤 변수끼리 관련이 크고 적은지 파악할 수 있다.
R에 내장된 mtcars 데이터를 이용해 상관행렬을 만들어 보자.
mtcars는 자동차 32종의 11개 속성에 대한 정보를 담고 있는 데이터이다.
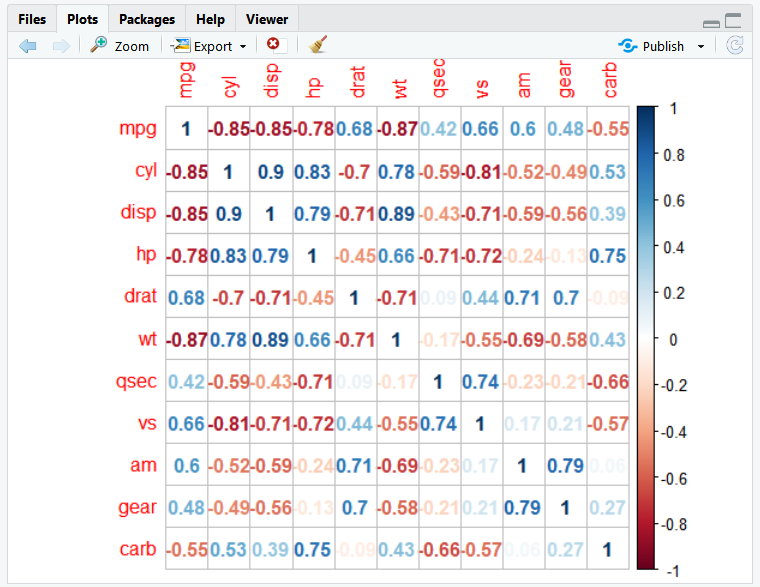
1. cor() 이용해 상관행렬 만들기
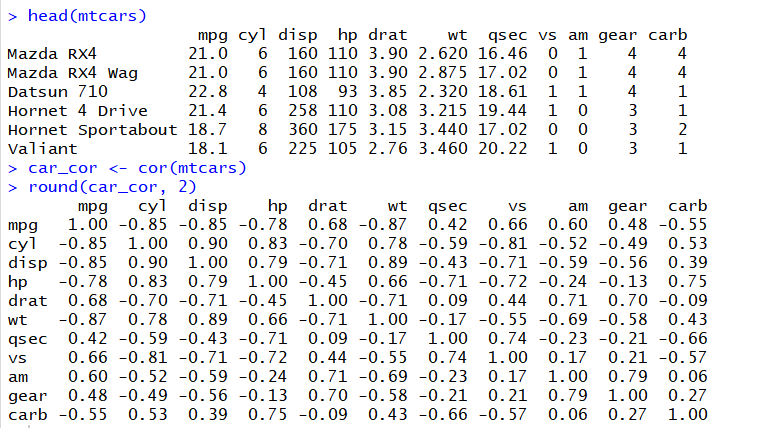
1. mpg행과 cyl 열이 교차되는 부분을 보면 상관계수가 -0.85 이므로, 연비가 높을 수록 실린더 수가 적은
경향이 있다는 것을 알 수 있다.
2. cyl 과 wt 의 상관계수가 0.78 이므로, 실런더 수가 많을수록 자동차가 무거운 경향이 있다는 것을 알 수 있다.
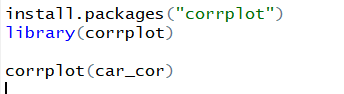
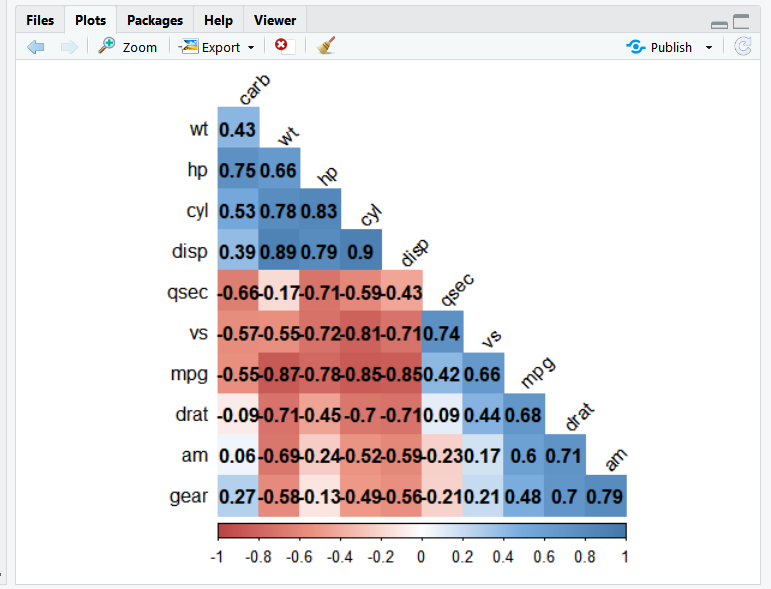
2. corrplot 패키지의 corrplot()을 이용해 상관행렬을 히트맵으로 만들면 변수들의 관계를 쉽게 파악 할 수 있다.
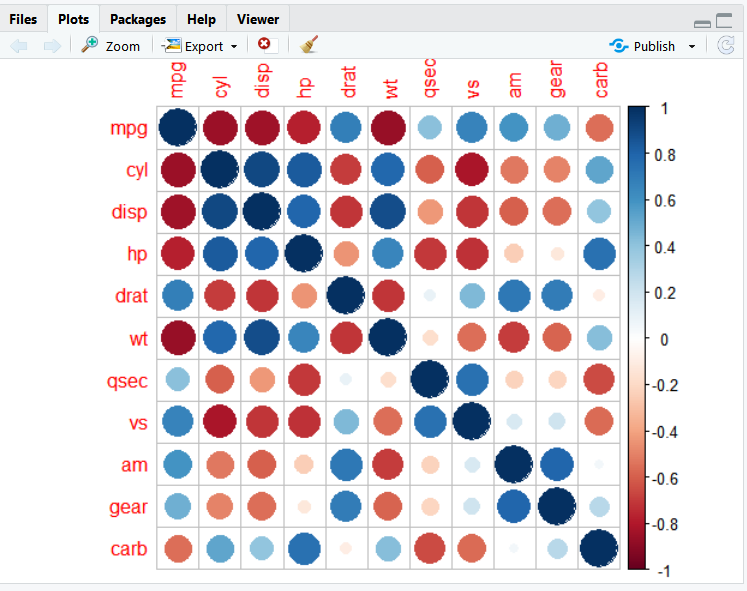
출력된 히트맵을 보면 상관계수가 클수록 원의 크기가 크고 색깔이 진하다.
상관계수가 양수면 파란색, 음수면 빨간색 계열로 표현되어 있다.
원의 크기와 색깔을 보면 상관관계의 정도와 방향을 쉽게 파악할 수 있다.
3. corrplot()의 파라미터를 이용해 그래프 형태를 다양하게 바꿀 수 있다.
method 에 "number"를 지정해 원 대신 상관계수가 표현되게 설정하자.
corrplot(car_cor, method = "number")
4. colorRampPalette() 로 색상 코드 목록을 생성한 후 col 파라미터에 지정하자.

출처: 김영우, "쉽게 배우는 R 데이터 분석", 이지스퍼블리싱, 2017년, 298-307쪽
'수업후기 > 확률과 통계' 카테고리의 다른 글
| MarkDown VS MarkUp (1) | 2019.05.30 |
|---|---|
| 통계적 가설 검정 이론 (0) | 2019.05.30 |
| 10-2 강: R Markdown 으로 데이터 분석 보고서 만들기 (0) | 2019.05.26 |
| 10-1강 : 인터랙티브 그래프 (0) | 2019.05.26 |
| WordCloud2 (0) | 2019.05.23 |